Code
library(stargazer)
#library(MASS)
library(openxlsx)
#library(viridis)
library(kableExtra)
library(vtable)
library(Hmisc)
library(huxtable)
library(tidyverse)Das fertige Paper kann über diesen Button heruntergeladen werden:
library(stargazer)
#library(MASS)
library(openxlsx)
#library(viridis)
library(kableExtra)
library(vtable)
library(Hmisc)
library(huxtable)
library(tidyverse)# Importing IPO Data
data_ipo_complete <- read_csv("data_ipo.csv") %>%
janitor::clean_names() %>%
select("date" = dates_issue_date,
"issuer_name" = issuer_borrower_name_full,
"issuer_sector" = issuer_borrower_trbc_economic_sector,
"issuer_nation" = issuer_borrower_nation,
"proceeds" = proceeds_amount_incl_overallotment_sold_all_markets,
"ipo_offer_price" = new_issues_offer_price,
"ipo_closing_price" = stock_price_at_close_of_issue_date,
isin,
"pe" = financials_price_earnings_ratio_before_offering_percent,
#"pb_before" = financials_price_book_value_before_offer,
"pb" = financials_price_book_value_after_offer,
"ebitda" = financials_ebitda_before_offering_host_currency,
"founding_date" = new_issues_date_company_founded) %>%
mutate(founding_date = dmy(str_extract(founding_date, "\\d+/\\d+/\\d+")),
age = as.numeric(date - founding_date) / 365.25)Warning: There was 1 warning in `mutate()`.
ℹ In argument: `founding_date = dmy(str_extract(founding_date,
"\\d+/\\d+/\\d+"))`.
Caused by warning:
! 174 failed to parse.data_ipo_incorporation <- read.xlsx("IPOs_AIM.xlsx", sheet = "AGE") %>%
janitor::clean_names() %>%
select(isin, dates_issue_date, date_of_incorporation) %>%
mutate(dates_issue_date = as.Date(dates_issue_date, origin = "1899-12-30"),
date_of_incorporation = as.Date(date_of_incorporation, origin = "1899-12-30")) %>%
mutate(age = as.numeric(dates_issue_date - date_of_incorporation) / 365.25) %>%
select(isin, age)
data_ipo_raw <- read.xlsx("IPOs_AIM.xlsx", sheet = "ISIN_Filter") %>%
janitor::clean_names() %>%
select("date" = dates_issue_date,
"name" = issuer_borrower_name_full,
"nation" = issuer_borrower_nation,
"proceeds" = proceeds_amount_incl_overallotment_sold_all_markets,
"technique" = offering_technique,
"subregion" = domicile_nation_sub_region,
"sector" = issuer_borrower_trbc_economic_sector,
"ticker" = new_issues_primary_ticker_symbol,
"isin" = isin) %>%
mutate(date = as.Date(date, origin = "1899-12-30")) %>%
group_by(isin) %>%
filter(row_number() == 1) %>%
left_join(data_ipo_incorporation, by = "isin") %>%
left_join(data_ipo_complete %>%
group_by(isin) %>%
filter(row_number() == 1) %>%
select(isin,
"offer_price" = ipo_offer_price,
"closing_price" = ipo_closing_price,
pe:ebitda),
by = "isin") %>%
mutate(return = closing_price / offer_price - 1)
rm(data_ipo_complete)
data_ipo_raw# Importing index timeseries
data_ftais_daily <- read_csv("ftais_ts_daily.csv") %>%
rename("date" = Date,
"ftais_closing_price" = CLOSE) %>%
mutate(ftais_return = (ftais_closing_price - lag(ftais_closing_price)) / lag(ftais_closing_price))
data_smx_daily <- read.xlsx("FTSE_SMALL_CAP.xlsx", startRow = 5) %>%
remove_rownames() %>%
janitor::clean_names() %>%
rename("date" = code,
"smx_closing_price" = ftsesco_ri) %>%
mutate(date = as.Date(date, origin = "1899-12-30")) %>%
mutate(smx_return = (smx_closing_price - lag(smx_closing_price)) / lag(smx_closing_price))
data_index_daily <- data_smx_daily %>%
left_join(data_ftais_daily, by = "date") %>%
filter(date >= ymd("2010-01-01")) %>%
drop_na() %>%
mutate_at(vars(smx_return, ftais_return), ~replace_na(., 0)) %>%
mutate(smx_closing_price = smx_closing_price / first(smx_closing_price) * 100) %>%
mutate(ftais_closing_price = ftais_closing_price / first(ftais_closing_price) * 100)# Importing and Cleaning Return Data
data_returns_raw <- read.xlsx("Returns_Prices_AIM.xlsx", sheet = "Return_Index_Clean", startRow = 1) %>%
mutate(date = as.Date(date, origin = "1899-12-30")) %>%
pivot_longer(cols = -date, names_to = "isin", values_to = "return_index") %>%
mutate(isin = str_remove(isin, "\\(RI\\)")) %>%
drop_na() %>%
group_by(isin) %>%
arrange(date, .by_group = TRUE) %>%
mutate(return = (return_index - lag(return_index)) / lag(return_index),
return = replace_na(return, 0)) %>%
mutate(return_index = return_index / (first(return_index, na_rm = TRUE)*0.01)) %>% # some do not start at 100
drop_na()
# Extracting first trading day
first_trading_day <- data_returns_raw %>%
group_by(isin) %>%
dplyr::summarize(first_date = min(date, na.rm = TRUE))
# Extracting last trading day and Name
last_trading_day <- read.xlsx("Returns_Prices_AIM.xlsx", sheet = "ISIN_Name") %>%
mutate(isin = str_remove(isin, "\\(RI\\)"),
name = str_remove(name, " - TOT RETURN IND"),
last_date = mdy(str_extract(name, regex("\\d{2}/\\d{2}/\\d{2}")), quiet = TRUE),
name = str_remove(name, regex(" DEAD.*")))
# Adding first and last day of trading
data_returns <- data_returns_raw %>%
left_join(first_trading_day, by = "isin") %>%
left_join(last_trading_day, by = "isin") %>%
select(date, isin, name, first_date, last_date, return_index, return) %>%
mutate(trading_day = row_number(),
trading_month = ceiling(trading_day / 21))
data_returns# Summary statistics table of IPO data
data_ipo_rawvtable::sumtable(data_ipo_raw %>% filter(!is.na(return)), add.median = TRUE, out = "return") %>%
group_by_all() # for better quarto rendering, dont know why that ismcor <- data_ipo_raw %>%
ungroup() %>%
filter(!is.na(return)) %>%
select_if(is.numeric) %>%
as.matrix() %>%
rcorr() %>%
.$r
mcor[upper.tri(mcor)] <- NA
mcor %>%
round(2) %>%
as_tibble() %>%
group_by_all() # for better quarto rendering, dont know why that is# Tables for presentation
#c('notNA(x)','mean(x)','sd(x)','min(x)','pctile(x)[25]','pctile(x)[75]','max(x)')
vtable::sumtable(data_ipo_raw %>% filter(!is.na(return)), out = "return",
summ = c('notNA(x)','mean(x)','pctile(x)[25]','pctile(x)[50]','pctile(x)[75]')) %>%
group_by_all() # for better quarto rendering, dont know why that is# Plot: When do IPOs happen?
#data_ftais_daily
#data_ipo_raw %>%
# group_by(date) %>%
# count() %>%
# uncount(n) %>%
# mutate(ipo = 1) %>%
# right_join(data_index_daily, by = join_by(date)) %>%
# arrange(date) %>%
# filter(date > ymd("2010-01-01") & date < ymd("2019-12-31")) %>%
# ggplot()+
# geom_line(aes(x = date, y = ftais_closing_price, color = "FTAIS"),)+
# geom_line(aes(x = date, y = smx_closing_price, color = "SMX"))+
# geom_segment(data = . %>% filter(ipo == 1), aes(x = date, xend = date, y = 80, yend = ftais_closing_price),
# alpha = 0.2)+
# scale_x_date(date_breaks = "1 year", date_labels = "%Y")+
# scale_color_manual(values = c("FTAIS" = "black", "SMX" = "darkgrey"),
# name = "",
# labels = c("FTAIS", "SMX"))+
# labs(x = "",
# y = "Closing Price")+
# theme(legend.position = c(0.1, 0.9),
# legend.background = element_rect(fill = NA))
data_ipo_raw %>%
group_by(date) %>%
count() %>%
uncount(n) %>%
mutate(ipo = 1) %>%
right_join(data_index_daily, by = join_by(date)) %>%
arrange(date) %>%
filter(date > ymd("2010-01-01") & date < ymd("2019-12-31")) %>%
ggplot()+
geom_line(aes(x = date, y = ftais_closing_price),)+
geom_segment(data = . %>% filter(ipo == 1), aes(x = date, xend = date, y = 90, yend = ftais_closing_price),
alpha = 0.2)+
scale_x_date(date_breaks = "1 year", date_labels = "%Y")+
theme_bw()+
labs(x = "",
y = "Closing Price FTAIS")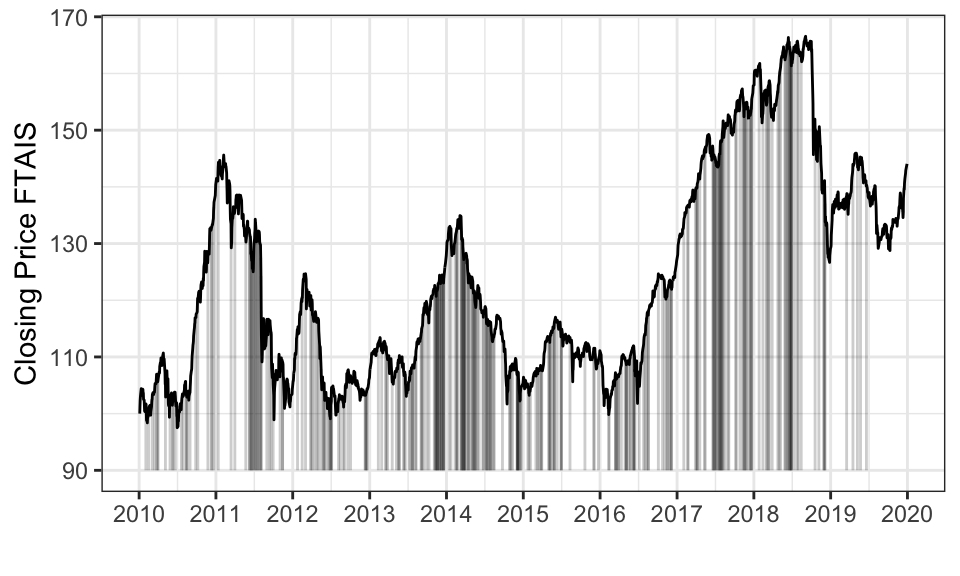
#ggsave(filename = "01_Abbildungen/FTAIS_timeseries.pdf", plot = last_plot(), width = 5, height = 3)# Plot FTAIS presentation
data_ipo_raw %>%
group_by(date) %>%
count() %>%
uncount(n) %>%
mutate(ipo = 1) %>%
right_join(data_index_daily, by = join_by(date)) %>%
arrange(date) %>%
filter(date > ymd("2010-01-01") & date < ymd("2019-12-31")) %>%
ggplot()+
geom_line(aes(x = date, y = ftais_closing_price),)+
geom_segment(data = . %>% filter(ipo == 1), aes(x = date, xend = date, y = 90, yend = ftais_closing_price),
alpha = 0.2)+
scale_x_date(breaks = seq(ymd("2010-01-01"), ymd("2020-01-01"), by = "2 years"), date_labels = "%Y")+
theme_bw()+
labs(x = element_blank(),
y = "Closing Price FTAIS")
#ggsave(filename = "01_Abbildungen/FTAIS_timeseries_presentation.png", plot = last_plot(), width = 3.5, height = 3)Im ersten Schritt wird das kurzfristige Underpricing am Tag des IPOs berechnet. Dafür wird die IPO-Rendite \(r_{i,\text{IPO}}\) für jedes Wertpapier \(i\) wie folgt bestimmt:
\[ r_{i,\text{IPO}} = \frac{\text{Closing Price}_i}{\text{Offer Price}_i} - 1 \]
Wir sind jedoch mehr am marktadjustierten Underpricing interessiert. Dabei wird von der Rendite des ersten Tages die Rendite des bzw. eines Marktindexes \(r_{M}\) für den jeweiligen IPO-Tag abgezogen. Somit sollen tagesspezifische Einflüsse auf den IPO ausgeglichen werden. Das Ergebnis ist das sogenannte Adjusted-Underpricing \(r_{i,\text{IPO}-adj.}\) für Wertpapier \(i\) am IPO-Tag.
\[ r_{i,\text{IPO}-adj.} = r_{i,\text{IPO}} - r_{M} \]
Als Marktindex haben wir uns für den FTSE AIM All-Share Index entschieden. Dieser bildet die Marktbewegung einer Vielzahl von an der AIM gelisteten Unternehmen ab und ist somit am besten geeignet, für spezifische Einflüsse auf Unternehmen dieses Marktes zu korrigieren.
# Underpricing by year
data_underpricing <- data_ipo_raw %>%
ungroup() %>%
#select(date, return) %>%
inner_join(data_index_daily, by = "date") %>%
#drop_na() %>%
mutate(adjusted_return = return - ftais_return,
adjusted_return_smx = return - smx_return)
underpricing_year <- data_ipo_raw %>%
ungroup() %>%
select(date, return) %>%
inner_join(data_index_daily, by = "date") %>%
drop_na() %>%
mutate(year = year(date)) %>%
group_by(year) %>%
summarise(n = n(),
return = mean(return),
market_return = mean(ftais_return),
adjusted_return = mean(return - ftais_return))
data_ipo_raw %>%
ungroup() %>%
select(date, return) %>%
inner_join(data_index_daily, by = "date") %>%
drop_na() %>%
mutate(year = year(date)) %>%
group_by(year) %>%
ggplot(aes(x = year, y = return - ftais_return, group = year))+
geom_boxplot()+
scale_x_continuous(breaks = 2010:2019,
labels = paste(underpricing_year$year, "\n", "n=", underpricing_year$n, sep = ""))+
scale_y_continuous(breaks = seq(from = -1, to = 2.5, by = 0.5))+
theme_bw()+
labs(x = "",
y = "market adjusted underpricing")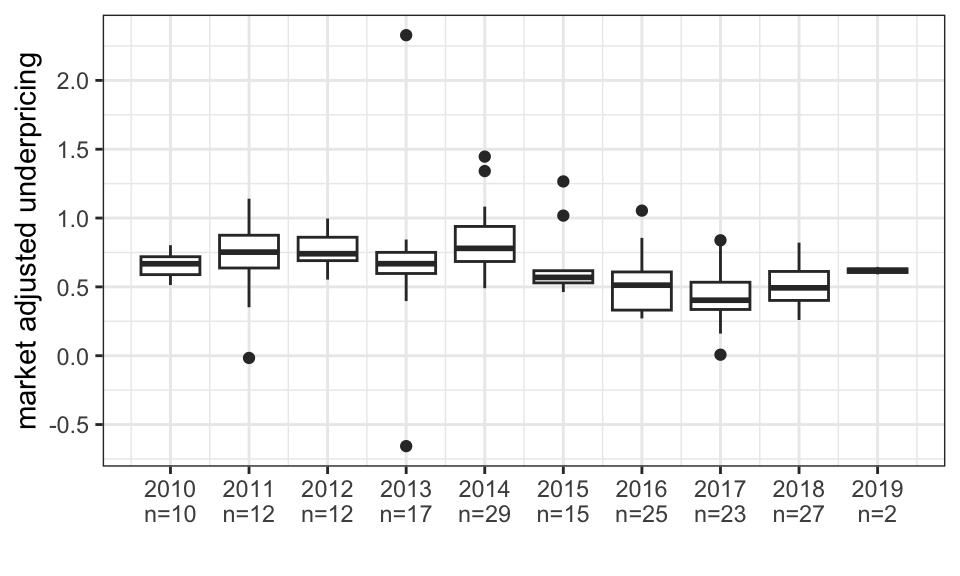
#ggsave("01_Abbildungen/underpricing_year.pdf", plot = last_plot(), width = 5, height = 3)# Plot presentation
data_ipo_raw %>%
ungroup() %>%
select(date, return) %>%
inner_join(data_index_daily, by = "date") %>%
drop_na() %>%
mutate(year = year(date)) %>%
group_by(year) %>%
ggplot(aes(x = year, y = return - ftais_return, group = year))+
geom_boxplot()+
scale_x_continuous(breaks = 2010:2019,
labels = paste(underpricing_year$year, "\n", "(", underpricing_year$n, ")", sep = ""))+
scale_y_continuous(breaks = seq(from = -1, to = 2.5, by = 0.5))+
theme_bw()+
labs(x = element_blank(),
y = "Market Adjusted Underpricing")
#ggsave("01_Abbildungen/underpricing_year_presentation.png", plot = last_plot(), width = 4, height = 3)Es ergibt sich das folgende Regressionsmodell:
\[ \begin{aligned} r_{i,\text{IPO}-adj.} = \beta_0 &+ \beta_1 \cdot \text{proceeds}_i + \beta_2 \cdot \text{offer-price}_i + \beta_3 \cdot \text{pe}_i + \beta_4 \cdot \text{pb}_i \\ &+ \beta_5 \cdot \text{EBITDA}_i + \beta_6 \cdot \text{age}_i + \epsilon_i \end{aligned} \]
# Regression
# First regression with dataset and missing values
# But there are only 36 observations left then
data_ipo_raw %>%
ungroup() %>%
filter(!is.na(return),
!is.na(proceeds),
!is.na(offer_price),
!is.na(pe),
!is.na(pb),
!is.na(ebitda),
!is.na(age)) %>%
count() %>% pull(n)[1] 106reg_underpricing_1 <- lm(formula = adjusted_return ~ proceeds + offer_price + pe + pb + ebitda + age, data = data_underpricing)
#summary(reg_underpricing_1)
# Creating "second" dataset, where missing values are set to the conditional mean
# OLD:
#data_ipo_filled_mean <- data_underpricing %>%
# ungroup() %>%
# filter(!is.na(adjusted_return)) %>%
# mutate_at(vars(pe, pb, ebitda, age), ~replace_na(., mean(., na.rm = TRUE)))
# NEW: Conditional Mean Imputation
conditional_impute <- aregImpute(~ pe + pb + ebitda + age, data = data_underpricing, n.impute = 1)Iteration 1
Iteration 2
Iteration 3
Iteration 4 imputed_columns <- impute.transcan(conditional_impute, imputation = 1,
data = data_underpricing, list.out = TRUE, pr = FALSE, check = FALSE)
data_ipo_filled_mean <- data_underpricing %>%
select(-pe, -pb, -ebitda, -age) %>%
cbind(imputed_columns) %>%
filter(!is.na(adjusted_return))
data_ipo_filled_mean %>%
ungroup() %>%
filter(!is.na(return),
!is.na(proceeds),
!is.na(offer_price),
!is.na(pe),
!is.na(pb),
!is.na(ebitda),
!is.na(age)) %>%
count() %>% pull(n)[1] 172reg_underpricing_2 <- lm(formula = adjusted_return ~ proceeds + offer_price + pe + pb + ebitda + age, data = data_ipo_filled_mean)
#summary(reg_underpricing_2)
# Creating "third" dataset, where missing values are set to the conditional mean, but the three highest offer prices are filtered out
data_ipo_filled_mean_outliers <- data_ipo_filled_mean %>%
slice_min(n = -3, order_by = offer_price, with_ties = FALSE)
data_ipo_filled_mean_outliers %>%
ungroup() %>%
filter(!is.na(return),
!is.na(proceeds),
!is.na(offer_price),
!is.na(pe),
!is.na(pb),
!is.na(ebitda),
!is.na(age)) %>%
count() %>% pull(n)[1] 169reg_underpricing_3 <- lm(formula = adjusted_return ~ proceeds + offer_price + pe + pb + ebitda + age, data = data_ipo_filled_mean_outliers)
#summary(reg_underpricing_3)
#stargazer(reg_underpricing_1, reg_underpricing_2, reg_underpricing_3, align = TRUE)
huxreg(reg_underpricing_1, reg_underpricing_2, reg_underpricing_3, error_pos = "right")| (1) | (2) | (3) | ||||
|---|---|---|---|---|---|---|
| (Intercept) | 0.544 *** | (0.048) | 0.656 *** | (0.031) | 0.646 *** | (0.038) |
| proceeds | 0.001 * | (0.000) | 0.001 * | (0.000) | 0.001 | (0.000) |
| offer_price | -0.004 | (0.039) | -0.089 *** | (0.019) | -0.063 | (0.034) |
| pe | -0.000 | (0.000) | -0.000 | (0.000) | -0.000 | (0.000) |
| pb | -0.000 | (0.001) | -0.000 | (0.001) | -0.000 | (0.001) |
| ebitda | 0.003 | (0.002) | 0.002 | (0.002) | 0.002 | (0.002) |
| age | 0.001 | (0.003) | 0.005 | (0.003) | 0.002 | (0.003) |
| N | 106 | 172 | 169 | |||
| R2 | 0.117 | 0.138 | 0.048 | |||
| logLik | 8.098 | -13.123 | -11.520 | |||
| AIC | -0.196 | 42.245 | 39.039 | |||
| *** p < 0.001; ** p < 0.01; * p < 0.05. | ||||||
# Regression with SMX market adjustment
reg_underpricing_1_smx <- lm(formula = adjusted_return_smx ~ proceeds + offer_price + pe + pb + ebitda + age, data = data_underpricing)
# Comparison of the adjusted_return and adjusted_return_smx
reg_underpricing_comp <- list(reg_underpricing_1, reg_underpricing_1_smx)
#stargazer(reg_underpricing_comp, align = TRUE) %>%
# cat()
huxreg(reg_underpricing_1_smx, error_pos = "right")| (1) | ||
|---|---|---|
| (Intercept) | 0.543 *** | (0.047) |
| proceeds | 0.001 * | (0.000) |
| offer_price | -0.004 | (0.039) |
| pe | -0.000 | (0.000) |
| pb | -0.000 | (0.001) |
| ebitda | 0.003 | (0.002) |
| age | 0.001 | (0.003) |
| N | 106 | |
| R2 | 0.117 | |
| logLik | 8.357 | |
| AIC | -0.714 | |
| *** p < 0.001; ** p < 0.01; * p < 0.05. | ||
# Table for presentation
#stargazer(reg_underpricing_1, reg_underpricing_2, reg_underpricing_3, align = TRUE, df = FALSE, column.sep.width = "1pt")Für die Analyse der kurzfristigen Underperformance wird die Rendite in den ersten 30 Tagen nach dem IPO betrachtet. Dafür wird zuerst die Abnormal-Return (AR) jedes Wertpapiers \(i\) für Tag \(d\) bestimmt. \(d\) beschreibt dabei die Anzahl der Tage nach dem IPO, wobei der IPO-Tag auf 1 gesetzt wird. Damit lässt sich nun die Average-Abnormal-Return (AAR) für Tag \(d\) als Durchschnitt bestimmen.
\[ \begin{aligned} AR_{i,d} &= r_{i,d} - r_{M,d} \\ AAR_{d} &= \frac{1}{N} \sum_{i=1}^{N} AR_{i,d} \end{aligned} \]
Zum Abschluss wird die Cumulative-Abnormal-Return (CAR) sowie Cumulative-Average-Abnormal-Return (CAAR) für die ersten 30 Tage – ohne den IPO Tag – berechnet:
\[ \begin{aligned} CAR_i &= \sum_{d=2}^{31} AR_{i,d} \\ CAAR &= \frac{1}{N} \sum_{i=1}^{N} CAR_{i} \end{aligned} \]
# Merging AIM index to data_returns
data_returns_index <- data_returns %>%
left_join(data_index_daily, by = "date") %>%
mutate(ftais_return = replace_na(ftais_return, 0))
# Creating functions for t-statistic
calc_t_stat <- function(x) {
mean(x) / (sd(x) / sqrt(length(x)))
}
calc_p_value <- function(x) {
t_stat <- calc_t_stat(x)
df <- length(x) - 1
p_value <- 2 * (1 - pt(abs(t_stat), df=df))
return(p_value)
}
# Calculating daily benchmark-adjusted returns
CAAR <- data_returns_index %>%
mutate(ar = return - ftais_return) %>%
group_by(trading_day) %>%
filter(trading_day != 1,
trading_day <= 31) %>%
summarise(aar = mean(ar),
ar_t_stat = calc_t_stat(ar),
ar_p_value = calc_p_value(ar)) %>%
mutate(caar = cumsum(aar))# Recreating Table II from Ritter1991
CAAR %>%
mutate(aar = aar * 100,
caar = caar * 100) %>%
group_by_all() # for better quarto rendering, dont know why that is# kbl(
# format = "latex",
# digits = 2,
# booktabs = T,
# toprule = "\\hline \\hline",
# midrule = "\\hline",
# bottomrule = "\\hline \\hline",
# linesep = c("", "", "", "", "", "\\addlinespace")
# ) %>%
# cat()# Recreate Figure 1 from Ritter1991
data_returns_index %>%
mutate(ar = return - ftais_return) %>%
group_by(trading_day) %>%
filter(trading_day != 1,
trading_day <= 31) %>%
summarise(aar = mean(ar),
mean_return = mean(return)) %>%
mutate(caar = cumsum(aar),
cum_mean_return = cumsum(mean_return)) %>%
select(-aar, -mean_return) %>%
pivot_longer(cols = c(caar, cum_mean_return)) %>%
ggplot(aes(x = trading_day, y = value, linetype = name))+
geom_line()+
theme_bw()+
scale_x_continuous(breaks=seq(0, 32, by=2))+
scale_linetype_manual(values = c("solid", "dashed"), labels = c("CAAR", "Raw Return"))+
theme(legend.position = "top")+
labs(x = "Day of trading",
y = "Cumulative Return",
linetype = "")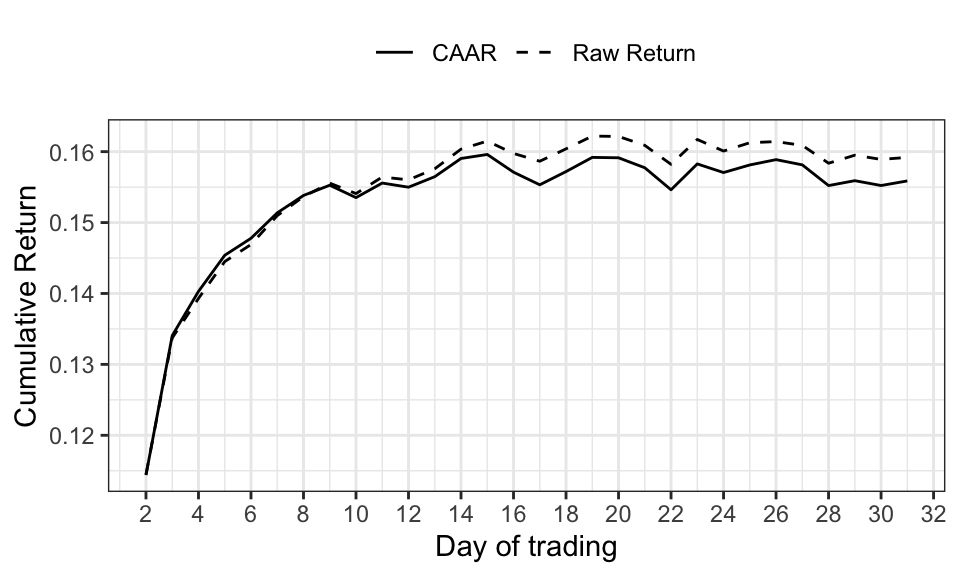
#ggsave(filename = "01_Abbildungen/CAR_underperformance.pdf", plot = last_plot(), width = 5, height = 3)# CAR plot presentation
data_returns_index %>%
mutate(ar = return - ftais_return) %>%
group_by(trading_day) %>%
filter(trading_day != 1,
trading_day <= 31) %>%
summarise(aar = mean(ar),
mean_return = mean(return),
median_ar = median(return)) %>%
mutate(caar = cumsum(aar),
cum_mean_return = cumsum(mean_return)) %>%
select(-aar, -mean_return) %>%
pivot_longer(cols = c(caar, cum_mean_return)) %>%
ggplot(aes(x = trading_day, y = value, linetype = name))+
geom_line()+
theme_bw()+
scale_x_continuous(breaks=seq(0, 30, by=5))+
scale_y_continuous(labels = scales::percent)+
scale_linetype_manual(values = c("solid", "dashed"), labels = c("Mean CAR", "Mean Raw Return"))+
theme(legend.position = c(0.7, 0.3),
legend.background = element_rect(fill = "transparent"))+
labs(x = "Day of trading",
y = "Cumulative Return",
linetype = "")
#ggsave(filename = "01_Abbildungen/CAR_underperformance_presentation.png", plot = last_plot(), width = 4, height = 3)Anschließend stellen wir ein Regressionsmodell mit der CAR als abhängige Variable auf. Als erklärende Variablen werden die gleichen Variablen wie bei der Regression zum Underpricing verwendet. Zusätzlich wird das Underpricing selbst als erklärende Variable in die Regression aufgenommen.
\[ \begin{aligned} \text{car}_{D,i} = \beta_0 &+ \beta_1 \cdot \text{proceeds}_i + \beta_2 \cdot \text{offer-price}_i + \beta_3 \cdot \text{pe}_i + \beta_4 \cdot \text{pb}_i \\ &+ \beta_5 \cdot \text{EBITDA}_i + \beta_6 \cdot \text{age}_i + \beta_7 \cdot \text{underpricing}_i + \epsilon_i \end{aligned} \]
# Regression CAR
data_reg_car <- data_returns_index %>%
mutate(ar = return - ftais_return) %>%
group_by(isin) %>%
arrange(isin, trading_day) %>%
filter(trading_day != 1) %>%
mutate(car = cumsum(ar))
# 5 days after IPO
reg_car_5 <- data_reg_car %>%
filter(trading_day == 5) %>%
rename("car_5" = car) %>%
left_join(data_ipo_raw, by = "isin") %>%
rename("underpricing" = return.y) %>%
lm(formula = car_5 ~ proceeds + offer_price + pe + pb + ebitda + age + underpricing, data = .)
#summary(reg_car_5)
reg_car_5_mean_filled <- data_reg_car %>%
filter(trading_day == 5) %>%
rename("car_5" = car) %>%
left_join(data_ipo_filled_mean, by = "isin") %>%rename("underpricing" = return.y) %>%
lm(formula = car_5 ~ proceeds + offer_price + pe + pb + ebitda + age + underpricing, data = .)
#summary(reg_car_5_mean_filled)
# 20 days after IPO
reg_car_20 <- data_reg_car %>%
filter(trading_day == 20) %>%
rename("car_20" = car) %>%
left_join(data_ipo_raw, by = "isin") %>%
rename("underpricing" = return.y) %>%
lm(formula = car_20 ~ proceeds + offer_price + pe + pb + ebitda + age + underpricing, data = .)
#summary(reg_car_20)
reg_car_20_mean_filled <- data_reg_car %>%
filter(trading_day == 20) %>%
rename("car_20" = car) %>%
left_join(data_ipo_filled_mean, by = "isin") %>%rename("underpricing" = return.y) %>%
lm(formula = car_20 ~ proceeds + offer_price + pe + pb + ebitda + age + underpricing, data = .)
#summary(reg_car_20_mean_filled)
# 30 days after IPO
reg_car_30 <- data_reg_car %>%
filter(trading_day == 30) %>%
rename("car_30" = car) %>%
left_join(data_ipo_raw, by = "isin") %>%
rename("underpricing" = return.y) %>%
lm(formula = car_30 ~ proceeds + offer_price + pe + pb + ebitda + age + underpricing, data = .)
#summary(reg_car_30)
reg_car_30_mean_filled <- data_reg_car %>%
filter(trading_day == 30) %>%
rename("car_30" = car) %>%
left_join(data_ipo_filled_mean, by = "isin") %>%
rename("underpricing" = return.y) %>%
lm(formula = car_30 ~ proceeds + offer_price + pe + pb + ebitda + age + underpricing, data = .)
#summary(reg_car_30_mean_filled)
# Stargazer
reg_car <- list(reg_car_5, reg_car_5_mean_filled, reg_car_20, reg_car_20_mean_filled, reg_car_30, reg_car_30_mean_filled)
#stargazer(reg_car, align = TRUE, omit.stat=c("f", "ser")) # old
#stargazer(reg_car, align = TRUE, df = FALSE, column.sep.width = "1pt")
huxreg(reg_car, error_pos = "right")| (1) | (2) | (3) | (4) | (5) | (6) | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| (Intercept) | -0.155 ** | (0.049) | -0.085 * | (0.038) | -0.114 | (0.063) | -0.090 | (0.049) | -0.150 * | (0.074) | -0.116 | (0.060) |
| proceeds | -0.000 | (0.000) | -0.000 | (0.000) | -0.001 | (0.000) | -0.001 | (0.000) | -0.001 | (0.000) | -0.000 | (0.000) |
| offer_price | 0.001 | (0.027) | 0.014 | (0.013) | 0.007 | (0.034) | 0.028 | (0.017) | 0.009 | (0.040) | 0.029 | (0.020) |
| pe | 0.000 | (0.000) | 0.000 | (0.000) | 0.000 | (0.000) | 0.000 | (0.000) | 0.000 | (0.000) | 0.000 | (0.000) |
| pb | -0.000 | (0.000) | -0.000 | (0.000) | -0.000 | (0.000) | -0.000 | (0.000) | -0.000 | (0.001) | -0.000 | (0.001) |
| ebitda | -0.001 | (0.001) | 0.001 | (0.001) | -0.001 | (0.002) | 0.001 | (0.002) | -0.001 | (0.002) | 0.001 | (0.002) |
| age | 0.002 | (0.002) | 0.000 | (0.002) | -0.000 | (0.003) | -0.001 | (0.002) | 0.002 | (0.003) | -0.000 | (0.003) |
| underpricing | 0.478 *** | (0.068) | 0.283 *** | (0.049) | 0.453 *** | (0.088) | 0.328 *** | (0.063) | 0.484 *** | (0.103) | 0.341 *** | (0.077) |
| N | 106 | 158 | 106 | 158 | 106 | 158 | ||||||
| R2 | 0.349 | 0.199 | 0.220 | 0.163 | 0.193 | 0.126 | ||||||
| logLik | 50.201 | 64.918 | 23.552 | 25.033 | 6.595 | -5.775 | ||||||
| AIC | -82.402 | -111.835 | -29.103 | -32.065 | 4.810 | 29.551 | ||||||
| *** p < 0.001; ** p < 0.01; * p < 0.05. | ||||||||||||
# Regression CAR with SMX market adjustment
data_reg_car_smx <- data_returns_index %>%
mutate(smx_return = replace_na(smx_return, 0)) %>%
mutate(ar = return - smx_return) %>%
group_by(isin) %>%
arrange(isin, trading_day) %>%
filter(trading_day != 1) %>%
mutate(car = cumsum(ar))
# 5 days after IPO
reg_car_5_smx <- data_reg_car_smx %>%
filter(trading_day == 5) %>%
rename("car_5" = car) %>%
left_join(data_ipo_raw, by = "isin") %>%
rename("underpricing" = return.y) %>%
lm(formula = car_5 ~ proceeds + offer_price + pe + pb + ebitda + age + underpricing, data = .)
#summary(reg_car_5)
reg_car_5_mean_filled_smx <- data_reg_car_smx %>%
filter(trading_day == 5) %>%
rename("car_5" = car) %>%
left_join(data_ipo_filled_mean, by = "isin") %>%rename("underpricing" = return.y) %>%
lm(formula = car_5 ~ proceeds + offer_price + pe + pb + ebitda + age + underpricing, data = .)
#summary(reg_car_5_mean_filled)
# 20 days after IPO
reg_car_20_smx <- data_reg_car_smx %>%
filter(trading_day == 20) %>%
rename("car_20" = car) %>%
left_join(data_ipo_raw, by = "isin") %>%
rename("underpricing" = return.y) %>%
lm(formula = car_20 ~ proceeds + offer_price + pe + pb + ebitda + age + underpricing, data = .)
#summary(reg_car_20)
reg_car_20_mean_filled_smx <- data_reg_car_smx %>%
filter(trading_day == 20) %>%
rename("car_20" = car) %>%
left_join(data_ipo_filled_mean, by = "isin") %>%rename("underpricing" = return.y) %>%
lm(formula = car_20 ~ proceeds + offer_price + pe + pb + ebitda + age + underpricing, data = .)
#summary(reg_car_20_mean_filled)
# 30 days after IPO
reg_car_30_smx <- data_reg_car_smx %>%
filter(trading_day == 30) %>%
rename("car_30" = car) %>%
left_join(data_ipo_raw, by = "isin") %>%
rename("underpricing" = return.y) %>%
lm(formula = car_30 ~ proceeds + offer_price + pe + pb + ebitda + age + underpricing, data = .)
#summary(reg_car_30)
reg_car_30_mean_filled_smx <- data_reg_car_smx %>%
filter(trading_day == 30) %>%
rename("car_30" = car) %>%
left_join(data_ipo_filled_mean, by = "isin") %>%
rename("underpricing" = return.y) %>%
lm(formula = car_30 ~ proceeds + offer_price + pe + pb + ebitda + age + underpricing, data = .)
#summary(reg_car_30_mean_filled)
# Stargazer
reg_car_smx <- list(reg_car_5, reg_car_5_smx, reg_car_20, reg_car_20_smx, reg_car_30, reg_car_30_smx)
#stargazer(reg_car_smx, align = TRUE, df = FALSE, column.sep.width = "1pt") %>%
# cat()
huxreg(reg_car_smx, error_pos = "right")| (1) | (2) | (3) | (4) | (5) | (6) | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| (Intercept) | -0.155 ** | (0.049) | -0.152 ** | (0.049) | -0.114 | (0.063) | -0.108 | (0.064) | -0.150 * | (0.074) | -0.131 | (0.075) |
| proceeds | -0.000 | (0.000) | -0.000 | (0.000) | -0.001 | (0.000) | -0.001 | (0.000) | -0.001 | (0.000) | -0.001 | (0.000) |
| offer_price | 0.001 | (0.027) | 0.001 | (0.027) | 0.007 | (0.034) | 0.008 | (0.035) | 0.009 | (0.040) | 0.012 | (0.041) |
| pe | 0.000 | (0.000) | 0.000 | (0.000) | 0.000 | (0.000) | 0.000 | (0.000) | 0.000 | (0.000) | 0.000 | (0.000) |
| pb | -0.000 | (0.000) | -0.000 | (0.000) | -0.000 | (0.000) | -0.000 | (0.000) | -0.000 | (0.001) | -0.000 | (0.001) |
| ebitda | -0.001 | (0.001) | -0.000 | (0.001) | -0.001 | (0.002) | -0.001 | (0.002) | -0.001 | (0.002) | -0.001 | (0.002) |
| age | 0.002 | (0.002) | 0.002 | (0.002) | -0.000 | (0.003) | -0.000 | (0.003) | 0.002 | (0.003) | 0.002 | (0.003) |
| underpricing | 0.478 *** | (0.068) | 0.471 *** | (0.068) | 0.453 *** | (0.088) | 0.432 *** | (0.089) | 0.484 *** | (0.103) | 0.439 *** | (0.104) |
| N | 106 | 106 | 106 | 106 | 106 | 106 | ||||||
| R2 | 0.349 | 0.341 | 0.220 | 0.202 | 0.193 | 0.164 | ||||||
| logLik | 50.201 | 49.862 | 23.552 | 21.994 | 6.595 | 4.911 | ||||||
| AIC | -82.402 | -81.724 | -29.103 | -25.988 | 4.810 | 8.177 | ||||||
| *** p < 0.001; ** p < 0.01; * p < 0.05. | ||||||||||||
# Table for regression
reg_car_presentation <- list(reg_car_5, reg_car_20, reg_car_30)
#stargazer(reg_car_presentation, align = TRUE, df = FALSE, column.sep.width = "1pt")# Plotting underpricing and CAR
data_returns_index %>%
mutate(ar = return - ftais_return) %>%
group_by(isin) %>%
arrange(isin, trading_day) %>%
filter(trading_day != 1) %>%
mutate(car = cumsum(ar)) %>%
filter(trading_day == 30) %>%
rename("car_30" = car) %>%
left_join(data_ipo_filled_mean, by = "isin") %>%
ggplot(aes(x = adjusted_return, car_30))+
geom_point()+
coord_cartesian(ylim = c(-1, 1))+
theme_bw()Warning: Removed 130 rows containing missing values (`geom_point()`).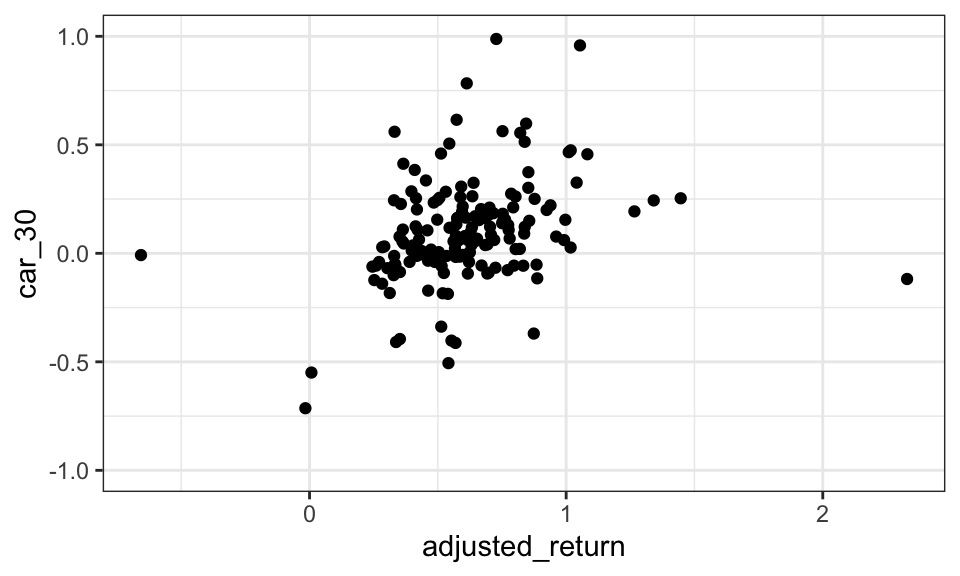
Die langfristige Underperformance wird anhand der Buy-And-Hold-Abnormal-Return (BHAR) bzw Buy-And-Hold-Average-Abnormal-Return (BHAAR) berechnet:
\[ \begin{aligned} BHAR_{i,M} &= \left( \prod_{m=1}^{M} (1+r_{i,m}) -1 \right) - \left( \prod_{m=1}^{M} (1+ \mathbf{E}[r_{i,m}]) -1 \right) \\ BHAAR_{M} &= \frac{1}{N} \sum_{i=1}^N BHAR_i \end{aligned} \] Dabei ist \(R_{it}\) die um Dividenden bereinigte Rendite des Wertpapiers \(i\) im Monat \(m\) nach dem IPO, \(N\) die Anzahl der Wertpapiere, \(M\) die Anzahl der Monate in der Betrachtung (für die Regression entsprechend 12, 36 oder 60) und \(\mathbf{E}[r_{i,m}]\) die erwartete Rendite in Monat \(m\), welche durch den FTAIS modelliert wird. Da uns tägliche und nicht monatliche Renditen vorliegen, werden zuerst die monatlichen Renditen nach dem folgenden Schema gebildet:
\[ \begin{aligned} r_{i,m=1} &= \prod_{d=2}^{22} (1 + r_{i,d}) - 1 \\ r_{i,m=2} &= \prod_{d=23}^{44} (1 + r_{i,d}) - 1 \\ r_{i,m=3} &= … \end{aligned} \]
Ein Monat ist dabei immer als 21 aufeinander folgende Handelstage definiert. Tag \(d = 1\) wird ausgelassen, da es sich dabei um den IPO-Tag handelt. Dieser wird bereits beim Thema Underpricing genauer betrachtet. Die gleiche Berechnung wird für den FTAIS Index durchgeführt.
# Calculating Buy-Hold-Abnormal-Returns (BHAR)
bhar_complete <- data_returns_index %>%
select(isin, date, last_date, return, trading_day, trading_month, ftais_return) %>%
group_by(isin) %>%
filter(is.na(last_date) | date < last_date) %>%
filter(trading_day != 1) %>%
mutate(return = if_else(return %in% c(Inf, -Inf), 0, return)) %>%
group_by(isin, trading_month) %>%
# aggregate by month
summarise(return = prod(1 + return) - 1,
ftais_return = prod(1 + ftais_return) - 1) %>%
group_by(isin) %>%
mutate(cum_return = cumprod(1 + return) - 1,
cum_ftais_return = cumprod(1 + ftais_return) - 1) %>%
mutate(bhar = cum_return - cum_ftais_return) %>%
ungroup()`summarise()` has grouped output by 'isin'. You can override using the
`.groups` argument.bhar <- bhar_complete %>%
group_by(trading_month) %>%
summarise(n = n(),
mean_bhar = mean(bhar),
t_stat = calc_t_stat(bhar),
p_value = calc_p_value(bhar),
median_bhar = median(bhar),
share_negative = sum(bhar < 0) / n())# Creating BHAR table
bhar %>%
filter(trading_month %in% c(seq(from = 0, to = 60, by = 6))) %>%
mutate(mean_bhar = mean_bhar * 100,
median_bhar = median_bhar * 100,
share_negative = share_negative * 100) %>%
group_by_all() # for better quarto rendering, dont know why that is# kbl(
# format = "latex",
# toprule = "\\hline \\hline",
# midrule = "\\hline",
# bottomrule = "\\hline \\hline",
# booktabs = T,
# digits = 2,
# #linesep = c("", "", "", "", "", "\\addlinespace")
# ) %>%
# cat()# BHAR table and plot presentation
bhar %>%
filter(trading_month %in% c(seq(from = 0, to = 60, by = 6))) %>%
mutate(mean_bhar = mean_bhar * 100,
median_bhar = median_bhar * 100,
share_negative = share_negative * 100) %>%
select(-c(p_value, share_negative)) %>%
group_by_all() # for better quarto rendering, dont know why that is
# kbl(
# format = "latex",
# toprule = "\\hline \\hline",
# midrule = "\\hline",
# bottomrule = "\\hline \\hline",
# booktabs = T,
# digits = 2,
# #linesep = c("", "", "", "", "", "\\addlinespace")
# ) %>%
# cat()
bhar %>%
filter(trading_month %in% c(seq(from = 0, to = 60, by = 1))) %>%
select(-c(p_value, share_negative, t_stat)) %>%
rbind(tibble(trading_month = 0, n = 288, mean_bhar = 0, median_bhar = 0)) %>%
pivot_longer(cols = c(mean_bhar, median_bhar)) %>%
ggplot()+
geom_line(aes(x = trading_month, y = value, color = name))+
geom_hline(yintercept = 0, linetype = "dotted")+
geom_text(data = . %>% filter(trading_month == 60),
aes(x = 65, y = value, label = paste(round(value*100), "%", sep = "")))+
scale_color_manual(values = c("mean_bhar" = "#005AA9", "median_bhar" = "#EC6500"),
labels = c("Mean", "Median")) +
scale_x_continuous(breaks = c(seq(0, 70, 6)), limits = c(0, 67)) +
scale_y_continuous(labels = scales::percent)+
theme_bw()+
theme(legend.position = c(0.15, 0.2),
legend.background = element_rect(fill = "transparent"))+
labs(color = "",
x = "Trading month",
y = "BHAR")
#ggsave(filename = "01_Abbildungen/BHAR_presentation.png", plot = last_plot(), width = 4, height = 3)# BHAR plot
bhar_complete %>%
filter(trading_month %in% c(seq(from = 0, to = 60, by = 6))) %>%
ggplot(aes(x = trading_month, y = bhar, group = trading_month))+
geom_boxplot()+
coord_cartesian(ylim = c(-2, 4))+
theme_bw()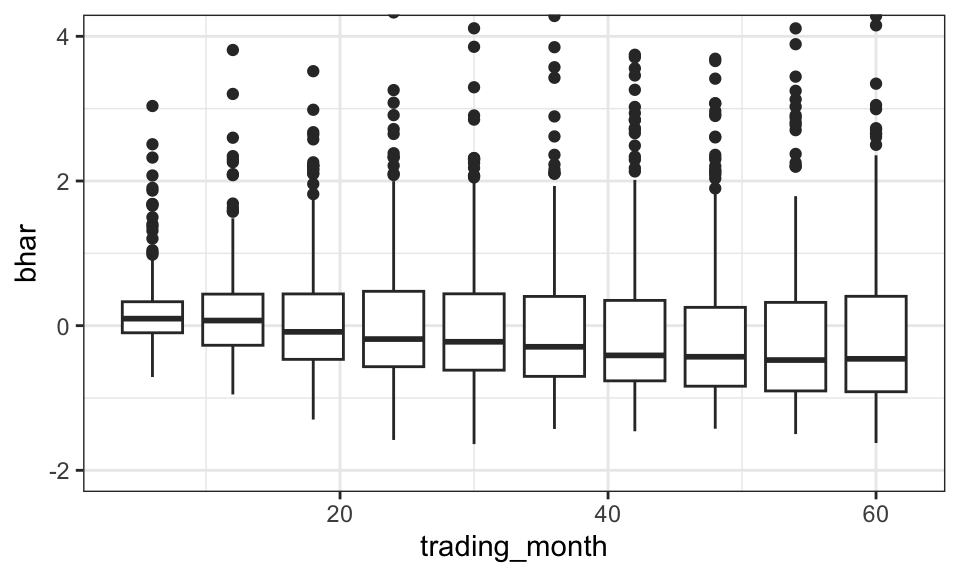
Schließlich untersuchen wir, ob es einen Zusammenhang zwischen Underpricing und Underperformance gibt. Dazu verwenden wir ein Regressionsmodell, in dem die langfristige Underperformance (BHAR) durch die Variablen, die Bereits in der Regression zum Underpricing verwendet wurden, erklärt wird. Zusätzlich wird das Underpricing selbst als Variable mit aufgenommen.
\[ \begin{aligned} \text{bhar}_{M,i} = \beta_0 &+ \beta_1 \cdot \text{proceeds}_i + \beta_2 \cdot \text{offer-price}_i + \beta_3 \cdot \text{pe}_i + \beta_4 \cdot \text{pb}_i \\ &+ \beta_5 \cdot \text{EBITDA}_i + \beta_6 \cdot \text{age}_i + \beta_7 \cdot \text{underpricing}_i + \epsilon_i \end{aligned} \]
# Regression BHAR
# 12 Months after IPO
reg_bhar_12 <- bhar_complete %>%
filter(trading_month == 12) %>%
rename(bhar_12 = bhar) %>%
left_join(data_ipo_raw, by = "isin") %>%
rename(underpricing = return.y) %>%
lm(formula = bhar_12 ~ proceeds + offer_price + pe + pb + ebitda + age + underpricing, data = .)
reg_bhar_12_mean_filled <- bhar_complete %>%
filter(trading_month == 12) %>%
rename(bhar_12 = bhar) %>%
left_join(data_ipo_filled_mean, by = "isin") %>%
rename(underpricing = return.y) %>%
lm(formula = bhar_12 ~ proceeds + offer_price + pe + pb + ebitda + age + underpricing, data = .)
# 36 Months after IPO
reg_bhar_36 <- bhar_complete %>%
filter(trading_month == 36) %>%
rename(bhar_36 = bhar) %>%
left_join(data_ipo_raw, by = "isin") %>%
rename(underpricing = return.y) %>%
lm(formula = bhar_36 ~ proceeds + offer_price + pe + pb + ebitda + age + underpricing, data = .)
reg_bhar_36_mean_filled <- bhar_complete %>%
filter(trading_month == 36) %>%
rename(bhar_36 = bhar) %>%
left_join(data_ipo_filled_mean, by = "isin") %>%
rename(underpricing = return.y) %>%
lm(formula = bhar_36 ~ proceeds + offer_price + pe + pb + ebitda + age + underpricing, data = .)
# 60 Months after IPO
reg_bhar_60 <- bhar_complete %>%
filter(trading_month == 60) %>%
rename(bhar_60 = bhar) %>%
left_join(data_ipo_raw, by = "isin") %>%
rename(underpricing = return.y) %>%
lm(formula = bhar_60 ~ proceeds + offer_price + pe + pb + ebitda + age + underpricing, data = .)
reg_bhar_60_mean_filled <- bhar_complete %>%
filter(trading_month == 60) %>%
rename(bhar_60 = bhar) %>%
left_join(data_ipo_filled_mean, by = "isin") %>%
rename(underpricing = return.y) %>%
lm(formula = bhar_60 ~ proceeds + offer_price + pe + pb + ebitda + age + underpricing, data = .)
# Stargazer
reg_bhar <- list(reg_bhar_12, reg_bhar_12_mean_filled, reg_bhar_36, reg_bhar_36_mean_filled, reg_bhar_60, reg_bhar_60_mean_filled)
#stargazer(reg_bhar, align = TRUE, omit.stat=c("f", "ser")) # old
#stargazer(reg_bhar, align = TRUE, df = FALSE, column.sep.width = "1pt")
huxreg(reg_bhar, error_pos = "right")| (1) | (2) | (3) | (4) | (5) | (6) | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| (Intercept) | 0.123 | (0.273) | 0.084 | (0.180) | -0.638 | (0.504) | -0.619 | (0.347) | -0.616 | (0.709) | -0.649 | (0.524) |
| proceeds | -0.001 | (0.002) | -0.001 | (0.001) | 0.005 | (0.003) | 0.005 * | (0.002) | 0.007 | (0.004) | 0.007 | (0.004) |
| offer_price | 0.033 | (0.147) | 0.034 | (0.061) | 0.189 | (0.270) | 0.127 | (0.116) | 0.089 | (0.380) | 0.073 | (0.172) |
| pe | 0.000 | (0.000) | 0.000 | (0.000) | 0.000 | (0.001) | 0.000 | (0.000) | 0.000 | (0.001) | 0.000 | (0.001) |
| pb | -0.002 | (0.002) | -0.002 | (0.002) | -0.001 | (0.004) | -0.002 | (0.004) | -0.002 | (0.005) | -0.003 | (0.005) |
| ebitda | 0.003 | (0.008) | 0.005 | (0.006) | -0.005 | (0.015) | -0.000 | (0.011) | 0.003 | (0.023) | 0.005 | (0.017) |
| age | 0.001 | (0.012) | 0.005 | (0.008) | 0.003 | (0.022) | 0.009 | (0.016) | 0.018 | (0.032) | 0.037 | (0.024) |
| underpricing | 0.227 | (0.378) | 0.119 | (0.231) | 0.565 | (0.696) | 0.495 | (0.444) | 0.608 | (0.992) | 0.528 | (0.673) |
| N | 106 | 158 | 102 | 151 | 94 | 136 | ||||||
| R2 | 0.022 | 0.027 | 0.086 | 0.080 | 0.072 | 0.074 | ||||||
| logLik | -131.424 | -180.093 | -187.575 | -269.420 | -203.533 | -294.021 | ||||||
| AIC | 280.848 | 378.187 | 393.150 | 556.839 | 425.066 | 606.041 | ||||||
| *** p < 0.001; ** p < 0.01; * p < 0.05. | ||||||||||||
# Regression BHAR SMX market adjustment
bhar_complete_smx <- data_returns_index %>%
select(isin, date, last_date, return, trading_day, trading_month, smx_return) %>%
group_by(isin) %>%
filter(is.na(last_date) | date < last_date) %>%
filter(trading_day != 1) %>%
mutate(return = if_else(return %in% c(Inf, -Inf), 0, return),
smx_return = replace_na(smx_return, 0)) %>%
group_by(isin, trading_month) %>%
# aggregate by month
summarise(return = prod(1 + return) - 1,
smx_return = prod(1 + smx_return) - 1) %>%
group_by(isin) %>%
mutate(cum_return = cumprod(1 + return) - 1,
cum_smx_return = cumprod(1 + smx_return) - 1) %>%
mutate(bhar = cum_return - cum_smx_return) %>%
ungroup()`summarise()` has grouped output by 'isin'. You can override using the
`.groups` argument.# 12 Months after IPO
reg_bhar_12_smx <- bhar_complete_smx %>%
filter(trading_month == 12) %>%
rename(bhar_12 = bhar) %>%
left_join(data_ipo_raw, by = "isin") %>%
rename(underpricing = return.y) %>%
lm(formula = bhar_12 ~ proceeds + offer_price + pe + pb + ebitda + age + underpricing, data = .)
reg_bhar_12_mean_filled_smx <- bhar_complete_smx %>%
filter(trading_month == 12) %>%
rename(bhar_12 = bhar) %>%
left_join(data_ipo_filled_mean, by = "isin") %>%
rename(underpricing = return.y) %>%
lm(formula = bhar_12 ~ proceeds + offer_price + pe + pb + ebitda + age + underpricing, data = .)
# 36 Months after IPO
reg_bhar_36_smx <- bhar_complete_smx %>%
filter(trading_month == 36) %>%
rename(bhar_36 = bhar) %>%
left_join(data_ipo_raw, by = "isin") %>%
rename(underpricing = return.y) %>%
lm(formula = bhar_36 ~ proceeds + offer_price + pe + pb + ebitda + age + underpricing, data = .)
reg_bhar_36_mean_filled_smx <- bhar_complete_smx %>%
filter(trading_month == 36) %>%
rename(bhar_36 = bhar) %>%
left_join(data_ipo_filled_mean, by = "isin") %>%
rename(underpricing = return.y) %>%
lm(formula = bhar_36 ~ proceeds + offer_price + pe + pb + ebitda + age + underpricing, data = .)
# 60 Months after IPO
reg_bhar_60_smx <- bhar_complete_smx %>%
filter(trading_month == 60) %>%
rename(bhar_60 = bhar) %>%
left_join(data_ipo_raw, by = "isin") %>%
rename(underpricing = return.y) %>%
lm(formula = bhar_60 ~ proceeds + offer_price + pe + pb + ebitda + age + underpricing, data = .)
reg_bhar_60_mean_filled_smx <- bhar_complete_smx %>%
filter(trading_month == 60) %>%
rename(bhar_60 = bhar) %>%
left_join(data_ipo_filled_mean, by = "isin") %>%
rename(underpricing = return.y) %>%
lm(formula = bhar_60 ~ proceeds + offer_price + pe + pb + ebitda + age + underpricing, data = .)
#
reg_bhar_smx <- list(reg_bhar_12, reg_bhar_12_smx, reg_bhar_36, reg_bhar_36_smx, reg_bhar_60, reg_bhar_60_smx)
#stargazer(reg_bhar_smx, align = TRUE, df = FALSE, column.sep.width = "1pt") %>%
# cat()
huxreg(reg_bhar_smx, error_pos = "right")| (1) | (2) | (3) | (4) | (5) | (6) | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| (Intercept) | 0.123 | (0.273) | 0.139 | (0.273) | -0.638 | (0.504) | -0.768 | (0.507) | -0.616 | (0.709) | -0.986 | (0.718) |
| proceeds | -0.001 | (0.002) | -0.001 | (0.002) | 0.005 | (0.003) | 0.005 | (0.003) | 0.007 | (0.004) | 0.007 | (0.004) |
| offer_price | 0.033 | (0.147) | 0.049 | (0.148) | 0.189 | (0.270) | 0.229 | (0.271) | 0.089 | (0.380) | 0.141 | (0.385) |
| pe | 0.000 | (0.000) | 0.000 | (0.000) | 0.000 | (0.001) | 0.000 | (0.001) | 0.000 | (0.001) | 0.000 | (0.001) |
| pb | -0.002 | (0.002) | -0.002 | (0.002) | -0.001 | (0.004) | -0.002 | (0.004) | -0.002 | (0.005) | -0.002 | (0.006) |
| ebitda | 0.003 | (0.008) | 0.002 | (0.008) | -0.005 | (0.015) | -0.006 | (0.015) | 0.003 | (0.023) | -0.000 | (0.023) |
| age | 0.001 | (0.012) | 0.002 | (0.012) | 0.003 | (0.022) | -0.002 | (0.023) | 0.018 | (0.032) | 0.012 | (0.032) |
| underpricing | 0.227 | (0.378) | 0.086 | (0.379) | 0.565 | (0.696) | 0.511 | (0.701) | 0.608 | (0.992) | 0.673 | (1.004) |
| N | 106 | 106 | 102 | 102 | 94 | 94 | ||||||
| R2 | 0.022 | 0.020 | 0.086 | 0.088 | 0.072 | 0.072 | ||||||
| logLik | -131.424 | -131.658 | -187.575 | -188.258 | -203.533 | -204.641 | ||||||
| AIC | 280.848 | 281.317 | 393.150 | 394.516 | 425.066 | 427.283 | ||||||
| *** p < 0.001; ** p < 0.01; * p < 0.05. | ||||||||||||
# Regression BHAR presentation
reg_bhar_presentation <- list(reg_bhar_12, reg_bhar_36, reg_bhar_60)
#stargazer(reg_bhar_presentation, align = TRUE, df = FALSE, column.sep.width = "1pt")